
TF-IDF算法介绍
TF-IDF(Term Frequency–Inverse Document Frequency),一种词频计算算法,等于某词在文档中出现概率 x 该词在所有文档中出现的概率的对数,即TF x IDF。
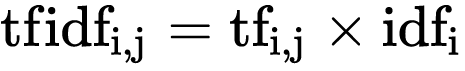
其中:TF和IDF的具体计算公式如下
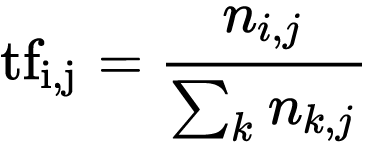
上式中n(ij)是该词在文件d(j)中出现的次数,而分母则是在文件d(j)中所有字词的出现次数之和。
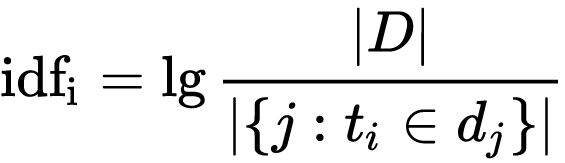
上式中
|D|:语料库中的文件总数
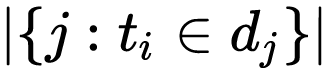
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在整个语料库中出现的频率成反比下降。这样就避免了一些不重要的词或语料库中广泛存在的词对统计结果造成影响,如a, the, of等。
举个例子:假如一篇文件的总词语数是100个,而词语“cow”出现了3次,那么“cow”一词在该文件中的词频(Term Frequency)就是3/100=0.03。
而计算逆向文件频率(IDF)的方法是以文件集的文件总数除以出现“cow”一词的文件数,并对结果求对数。所以,如果“cow”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率(IDF)就是lg(10,000,000 / 1,000)=4。
最后“cow”的TF-IDF的分数为 0.03 * 4 = 0.12
TF-IDF算法应用
搞清楚TF-IDF算法的原理后,具体TF-IDF算法可以应用在哪里呢?
考虑下面一个场景:你现在有有一些已分类的英文文章,还有n篇未分类的英文文章,你需要参考已分类文章内容,对这n篇未分类的文章进行分类。
要怎么做呢?很容易想到的一个思路是,根据已分类文章的内容,提取出文章的特征向量(这样就知道了文章里具体再说什么),再利用特征向量和对应的文章类别进行模型训练,训练好模型后,最后利用这个模型,利用未分类的文章的特征向量进行预测。
那么问题来了,怎样获取一篇文章的特征向量来区分它的类别呢?很显然,文章的分类跟它描述的内容紧密相关,也就是跟它里面使用的每个单词紧密相关。
这样一来,我们就可以利用TF-IDF算法,计算文章里面每个单词的TF-IDF值,得到文章的特征向量。
举个例子,假设我们只有下面2篇简短的文章:
文章A: The quick brown fox jumps over the lazy dog
文章B: Quick brown fox leaps over lazy dog in summer
我们可以根据文章A和文章B,获取包含全部单词的词表(词表按照字典排序):
[brown, dog, fox, in, jumps, lazy, leaps, over, quick, summer, the]
那么,我们令f(x) = tfidf(x),根据TF-IDF算法,计算文章A和文章B的特征向量为:
文章A: [f(brown), f(dog), f(fox), f(in)=0, f(jumps), f(lazy), f(leaps)=0, f(over), f(quick), f(summer)=0, f(the)]
文章B: [f(brown), f(dog), f(fox), f(in), f(jumps)=0, f(lazy), f(leaps), f(over), f(quick), f(summer), f(the)]
显然,当你对n篇文章进行特征向量计算时,你的词表里就不止上述的十几个单词了,通常会包含数千个单词。
好了,我们接下来看看实际情况下,我们是如何使用TF-IDF算法进行特征提取和预测的:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pylab as pl
import numpy as np
import math
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score
# 加载新闻数据
categories = [
'alt.atheism',
'talk.religion.misc',
'comp.graphics',
'sci.space',
]
removes = ('headers', 'footers', 'quotes')
data_train = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, remove=removes)
data_test = fetch_20newsgroups(subset='test', categories=categories, shuffle=True, remove=removes)
y_train, y_test = data_train.target, data_test.target
target_names = data_train.target_names
print "target_names: %s" % target_names
# 利用TFIDF把文本转为向量
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5, stop_words='english')
X_train = vectorizer.fit_transform(data_train.data)
X_test = vectorizer.transform(data_test.data)
feature_names = vectorizer.get_feature_names()
# 创建svm模型并训练
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
# 进行预测
y_predict = clf.predict(X_test)
print("Accuracy score:", accuracy_score(y_test, y_predict))
print("Predict: ", y_predict)输出内容如下:
target_names: ['alt.atheism', 'comp.graphics', 'sci.space', 'talk.religion.misc']
('Accuracy score:', 0.76866223207686624)
('Predict: ', array([2, 1, 1, ..., 2, 1, 1]))